С 2013 года в Традиции по рукам ходит документ 20 ключей Йог-Сотота. Текст документа составлен на Наг-Сотхе, одном из алфавитов традиции. При подстановке букв смысл документа не проясняется. Вероятно документ зашифрован. Документ подобного рода единственный из всех писаний Традиции присутствубщий в Фонде Наследия Великих Древних. Своеобразный Манускрипт Войнича)). Храм Древних, Фонд Наследия Великих Древних и журнал Апокриф анонсируют создание рабочей группы по дешифровке данного документа. Нам требуются: специалисты по доэнигмовской криптографии, и люди которые могут помочь в оцифровке документа с транслитерацией его в английский алфавит по рабочему шаблону. Для присоединения к рабочей группе необходимо иметь ящик на gmail и написать админу вконтакте. 20 Ключей Йог-Сотота https://vk.com/diongray - Вконтакте https://t.me/DionGray - Телеграм https://t.me/OldOnes - Общий чат Традиции в Телеграм
Если посмотреть на этот документ то можно обратить внимание что в надписях этих много повторений подрят одних и тех же букв, в обычных словах такого нет, значит там зашифрованны не слова. Что тогда? Возможно какой числовой ряд. Я думаю так что взяли этот афавит Наг-Сотхе и с помощью него передали какие то числа, а эти числа уже есть какой то ключ.
Добавлено (03.10.2016, 15:38) --------------------------------------------- Возможно тут имеется в виду двадцатеричная система счисления: "Двадцатеричная система используется во многих языках, в частности в языке йоруба, у тлинкитов, в системе записи чисел майя, некоторых кавказских и азиатских языках. Во многих (в основном европейских) языках используется основание 20, по крайней мере в лингвистической структуре." Вики
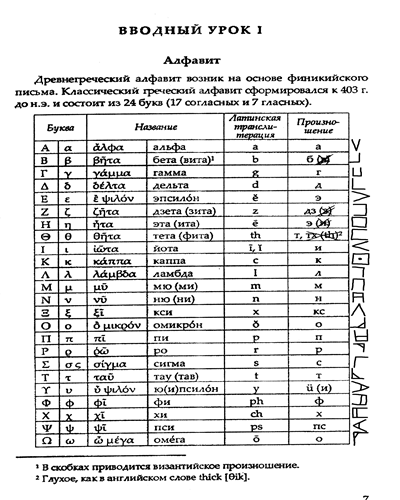
Чтобы не потерялось - краткие выводы при анализе 20-й страницы: 1. На странице 23 строки разной длины. На других страницах чисто строк может отличаться. 2. Если текст осмысленный, то используется алфавитная система, а не иероглифы, слоговые абугиды или что-то в этом роде. 3. На странице 20 использовано 22 буквы (как, например, в иврите). Есть ли другие буквы на других страницах - надо смотреть. 4. Смущает количество двойных букв, чуть ли не половина букв алфавита бывает в сдвоенной позиции (в русском языке могут дублироваться не более 13 букв, и то многие из них очень редко, а тут на одном листе 11. 5. Есть симметричные фрагменты формата ABBA, но такие в русском языке встречаются (пАССАжир, маккаВЕЕВ" и пр.), да и в других наверняка тоже. 6. Шифр Цезаря (шифр с равномерным сдвигом букв на несколько позиций) не даёт читаемых (даже с учётом возможных неточностей транскрипции) вариантов ни русской кириллицей, ни латиницей. 7. Частота букв не соответствует ни русской, ни английской, ни греческой, ни латинской, ни ивритской, ни большинства европейских, так что, скорее всего, это и не любой другой шифр, где происходит однозначная замена одной буквы на другую, а также не анаграмма. 8. В тексте не используется знаков, шифрующих пробел. 9. Скорее всего, нет и знаков, шифрующих знаки препинания. 10. В тексте отсутствуют (кроме единственного LLF, повторяющегося 2 раза) повторяющиеся трёх- и болеебуквенные сочетания - то есть, нет одинаковых слов, корней, суффиксов и пр. 11. Также это не шифр, где одна буква изображена сочетанием нескольких. 12. Шифром, где читаются только каждая вторая, третья и т. д. (проверял вплоть до 10-й) буква, этот текст тоже не является. 13. Самая частая буква более чем в полтора раза чаще, чем вторая по частоте, далее убывание плавное, перед предпоследней буквой снова скачок более чем в полтора раза. В английском, например, первый большой скачок тоже между 1-й и 2-й по частоте буквам, потом - между 9-й и 10-й, потом - между 11-й и 12-й - то есть, совсем другой "рисунок". В иврите - между 3-й и 4-й, и дальше тоже совсем по-другому. В русском тоже не похожий "рисунок". Теоретически, если удастся найти язык со схожей частотностью, можно будет попытаться расшифровывать на его основе, но вообще практически уверен, что это ничего не даст.
Конечно, это может быть какая-то более сложная форма шифра (например, читаться могут не все, а только некоторые из букв в определённом порядке), но тут можно строить много предположений, но без ключа они ничего не дадут. Почти уверен, что это пустышка, но теоретически возможно, например, что использовались несколько способов шифрования одновременно (тогда это не прочитать без ключа в принципе), или что прочитать можно только при наличии всего текста (например, читается 1-я буква 1-й страницы, потом 1-я буква 2-й, и т. д., или ещё какие-то подобные способы), или что использовался незнакомый язык с принципиально отличными от индоевропейских свойствами.
В общем, подобные подсчёты можно проводить сколько угодно, это ничего не даст. Надо всё же транскрибировать ещё несколько страниц и, как минимум, проверить, совпадает ли частота букв на разных страницах, а также нет ли каких-то межстраничных закономерностей.
Сообщение отредактировал otis - Вторник, 04.10.2016, 18:46
otis, классный анализ респект! Но есть еще один способ о котором вы не сказали, можно ведь читать буквы не только слева на право, но и справо налево и сверху вниз...как в некоторых языках. Возможно в этом плане стоит поискать.
Добавлено (04.10.2016, 15:43) --------------------------------------------- Попробуйте сгрупировать буквы так чтобы они все стояли друг под другом и прочитать сверху вниз этот документ.
Добавлено (04.10.2016, 16:03) --------------------------------------------- Ну вот я беру первую строку по вертикали переважу на английские буквы получается : C A T V N X H L I. Что то вроде Катун Ксели. Может это какие то древние заклинания?
Слева направо, справа налево, сверху вниз или в каком-то более сложном порядке (это фактически всего лишь разные варианты анаграммы, а об анаграмме я сказал), это не меняет дела насчёт частотного анализа: статистика не соответствует тем языкам, по которым я делал сравнение. Тем более что строки у нас разной длины, не получается всё читать по вертикали, не прибегая к дополнительным ухищрениям. Некоторые варианты дешифровки по ключу Цезаря, например, тоже давали вполне себе произносимые варианты (причём несколько вариантов), но так можно любые сочетания звуков объявить "заклинанием" и экспериментировать, "а что же получится" (особенно если объявить, что исходный язык похож на иврит, и труднопроизносимые места снабжать огласовками по собственному желанию - как было, например, при дешифровке енохианского). А чтобы говорить о дешифровке, этого всё-таки мало, надо найти хоть что-то заведомо осмысленное на одном из языков, причём чтобы один и тот же ключ работал и для остального текста. Единственное, что может как-то изменить полученные результаты - это транскрипция других страниц: чем больше текст, тем достовернее результаты статистики (например, если мы будем строить статистику только на скороговорке "на дворе трава", нам покажется, что "в" и "р" - самые частые согласные русского языка, но анализ "Евгения Онегина" или БСЭ, конечно, этого не подтвердит).
Сообщение отредактировал otis - Вторник, 04.10.2016, 21:47
Ну а что по вашему может быть в этом тексте? О чем там в принципе может идти речь? Ну типа что мы ищем? Очевидно что это какой то набор заклинаний, что то вроде Черной Скрижали.
Я тоже, судя по статистическим данным, думаю, что вряд ли. Но Чёрная Скрижаль встроена в осмысленный текст. Если нам достаточно непонятных заклинаний на непонятном языке - мы можем произвольно читать слева направо или справа налево, делать или не делать огласовки, воспринимать как анаграмму или читать только первые буквы в строках, сдвигать на любое количество позиций по ключу Цезаря или делать что угодно ещё, и у нас не будет причин предпочесть один вариант другому, если мы не можем сравнить их с известными языками или обнаружить явную закономерность. Даже если это древнее заклинание на неизвестном языке (в чём я сильно сомневаюсь, потому что оригинал, скорее всего, написан шариковой ручкой на белой бумаге), какой в этом смысл, если нет контекста с малейшим намёком на его использование? И вообще, если мы не надеемся найти что-то осмысленное, зачем что-то расшифровывать? Достаточно сделать прямую транскрипцию и снабдить огласовками. Тогда, например, первые строки 20-й страницы: J TLMQLZJBTSAINJQNIBAAFPO LOHIDRQ могут выглядеть, скажем, вот так: Ja! TaLM QuaL ZaJBaT SAIN JaQua NIBAAF PO! LOHIDR Qua! Ничуть не хуже, чем "Катун Ксели", и требует меньше допущений.
Добавлено (04.10.2016, 18:59) --------------------------------------------- Кстати, п. 10 (про отсутствие повторений) одинаково применим и к известным языкам, и к неизвестным. Маловероятно, что за страницу текста не попалось трёхбуквенных повторений - даже если это заклинание. Если какая-то схема прочтения (сверху вниз или как иначе) даст заметное количество повторений, пусть и не кажущихся осмысленными - это для меня будет важным аргументом в пользу того, что текст - не просто набор звуков (даже в заклинаниях должны быть некоторые общие слова - имена божеств, обращения, глаголы вроде "заклинаю" и пр.). Но, опять же, хотелось бы прогнать через этот пункт остальные страницы.
Добавлено (04.10.2016, 19:47) --------------------------------------------- Кстати, в Чёрной Скрижали многобуквенные повторы очень даже присутствуют - от слогов до словосочетаний. Так что, хоть язык и неидентифицируемый, признаки связного текста у него есть, даже если бы не был известен перевод.
Добавлено (04.10.2016, 21:15) --------------------------------------------- Проверил также частотность букв в енохианском. Снова никакого сходства.
Добавлено (04.10.2016, 21:38) --------------------------------------------- Проверил (и не нашёл ничего интересного) ещё несколько догадок, так что ещё несколько выводов:
1. Не заметно ли стеганографических приёмов - например, не выделены ли в оригинале какие-то отдельные символы каким-то особым способом. Например, некоторые могли бы быть написаны более жирно или более ровно, тогда, возможно, их следовало бы прочитать, а остальное могло бы быть мусором для отвода глаз. 2. Нет ли закономерностей в количестве знаков в разных строках (например, чёткое возрастание от 1 буквы в строке до полной строки). Это могло бы значить, что следует изменить порядок строк. Но такой последовательности не обнаружено, и иногда на одной странице есть несколько строк с одинаковым количеством символов. 3. Учитывая графику Нуг-Сота, допустимо также зеркальное прочтение. Однако оно не изменит частотных характеристик текста, так что особого смысла проверять эту версию нет. 4. Некоторые строки доходят до конца листа, поэтому не всегда понятно, переносится та же "фраза" на новую строку, или это новая "фраза". 5. На нескольких страницах число строк - 23, но, вероятно, это просто следствие размера листа и примерно одинаковых размеров букв, потому что на других страницах количество строк может и отличаться. 6. В нескольких случаях между строками есть явный промежуток вроде того, которое отделяет строфы стихотворения или законченные фрагменты прозаического текста. Размер "строф" может быть разным - от одной строки до целой страницы без разрывов. Закономерностей вроде короткой строки в начале или в конце "строфы" не обнаружено. 7. Декодер "кракозябр" тоже не дал ничего интересного, как и поиск в интернете слов средней длины вроде "QOFYFSFD" или "LOHIDRQ".
Добавлено (04.10.2016, 21:45) --------------------------------------------- Да, вот, на всякий случай, транскрипция 20-й страницы:
Добавлено (04.10.2016, 21:51) --------------------------------------------- Чтобы не забыть. Что нужно сделать, когда будет транскрибировано больше страниц:
1. Проверить, сильно ли изменится частотность. Если сильно - то приблизится ли она к частотности известных языков. 2. Проверить, много ли будет 3- и болеебуквенных повторов. 3. Посчитать и записать количество строк на каждой странице, букв в каждой строке, букв на каждой странице. Поискать в этом закономерности (учитывая, что доходящие до конца листа строки, возможно, переносятся на следующую строку), в том числе с учётом разрывов между "строфами". 4. Проверить варианты прочтения первых/последних букв разных страниц, разных "строф", другие возможные межстраничные последовательности.
Сообщение отредактировал otis - Вторник, 04.10.2016, 21:52
Можно как вариант попробовать и так, но суть в том, что частотные соотношения и отсутствие повторяющихся многобуквенных комбинаций будут одинаковыми при любом шифре простой замены.
Во втором классе мы с подружками усилено увлекались криптографией, делая свои записи не читаемыми для непосвященных. Сначала мы просто с энтузиазмом подменяли буквы алфавита на придуманные значки. Но тут я выяснила, что, оказывается, дешифровать такие тексты неприлично легко, если опираться на статистику встречаемости букв в тексте на определенном языке. Бардак...
Итогом предупреждения происков нахальных дешифровщиков стал шрифт, в котором требовалось минимально 13 символов. Максимально - до бесконечности, но прекрасный результат был бы уже на третьем десятке символов, я думаю. Суть такая: один символ у меня обозначал три последовательные буквы алфавита. Итого 11 "базовых" символов. К ним добавляем еще два символа: первый добавляется перед перед первой буквой из тройки, второй - перед последней. Перед второй буквой из тройки никаких дополнительных символов не ставится. Собственно, уже это делает простой подсчет статистики символов в тексте негодным методом его дешифровки. Но, догадавшись, какая примерно здесь использована система, разбить текст на реальные буквенные знаки все-таки вполне посильная задача.
А дальше наворачиваются извраты. Проще всего просто увеличить количество символов, которые обозначают одно и то же (а именно - первый символ из трио и последний). И расставлять их в тексте совершенно бессистемно, как пожелается левой ноге. Так, в тексте из 33 символов, к примеру, 11 символов будут обозначать тройку букв алфавита, еще около 11-ти - указывать на то, что надо дешифровывать, используя первую букву из трио, и еще около 11-ти - указывать на последнюю букву. Какой именно из этих 22-х допсимволов будет проставлен в конкретном месте текста? Любой. Эта часть шифра не подлежит никакой системе. Имея ключ, становится понятно, что эти несколько загогулин означают одно и то же и дешифровка идет в рабочем режиме. Не имея представления о том, какой знак означает буквы, а какой - дополнительный... Я не программист, поэтому вообще не представляю, какие аналитические методы можно использовать, чтобы свести такой шрифт к исходному смыслу. Зато на гора могу выдать еще несколько идей по усложнению ключа к шрифту, составленному на такой основе.
К чему я это? Да вот смотрю я на эти загогулины - и угадывается мне в них что-то очень знакомое. В частом повторении одних и тех же знаков в сочетании с достаточно небольшим количеством символов в целом. Идея соотнести знаки с буквами английского алфавита может оказаться провальной просто потому, что метод шифрования включает в себя элемент наличия некоторой бессистемности, использования части символов в хаотичном порядке; так сказать - "разрушения шаблона". Двойные символы могут оказаться как некой уловкой, которая не даст шанса использовать простые методы расшифровки, так и указывать на пробелы и знаки препинания.
Но, если текст не чья-то шутка - то он определенно составлен буквенными символами. А дальше надо хотя бы знать, о каком языке идет речь.
Еще такая была идея с самого начала что ключом должно стать слово Йог-Сотот. Надо найти его в тексте и соотнести с буквами. Yog - Sothoth, так наверное, найдите слово которое подошло бы и оно будет ключом к переводу.
Да, есть много сложных систем шифрования, не берущихся без ключа. Например, это вполне мог бы оказаться шифр Кронфельда (скажем, с ключом как раз YOGSOTHOTH), или книжный шифр (скажем, по Некрономикону Уилсона, откуда взят Нуг-Сот), где номера страницы/строки/буквы переданы буквами, или осмысленный текст может читаться буквами не через ровный интервал, а по какой-то сложной формуле, а остальные буквы могут быть добавлены произвольно для усложнения дешифровки, или ещё много вариантов, сам мог бы создать подобным образом выглядящий текст, который никто не расшифрует, если не будет знать всю последовательность ключей. Но, как правило, такие шифры достаточно молодые. Даже во времена Петра I "шифры простой подстановки" использовались достаточно широко - просто потому, что ВООБЩЕ ПИСЬМЕННОСТЬ была понятна далеко не всем. В 19-м веке считались диковинкой решётчатые шрифты, которые, по сути, являются или анаграммой, или текстом, перемежающимся "мусорными" буквами. Так что, если вообще браться за расшифровку, надо исходить из следующих тезисов (каждый из которых или все вместе могут быть ошибочными, но без которых вообще нет смысла браться за текст): 1. Текст осмысленный. 2. Текст шифровался единственным или парой последовательных несложных методов. 3. Текст написан на известном языке или, по крайней мере, на языке, схожем с известными по основным статистическим параметрам. Один из главных критериев осмысленного текста - это наличие повторов сочетаний знаков. Скажем, если в тексте будет несколько раз попадаться хотя бы слово "Йог-Сотот" (хоть в русском написании, сводимом к формуле ABCDBEBE, хоть в латинском - ABCDBEFBEF), эта последовательность будет легко обнаруживаться по двухбуквенным или трёхбуквенным фрагментам - BEBE ("отот") или BEFBEF ("othoth"), - соседствующим, к тому же, ещё с одной B (то есть букве "о"). Трёхбуквенных повторов, идущих подряд, на странице 20 не было (да и вообще был единственный трёхбуквенный повтор) - значит, надо присматриваться на других страницах и к этому тоже. Двухбуквенных, идущих подряд, кажется, тоже. Конечно, если текст идёт без огласовок, то эту закономерность мы тоже не выявим, но поискать слово "Йог-Сотот" - да, это дело. Но, судя по тому, что с повторами в тексте вообще негусто, есть большие сомнения, что это что-то даст. И если при каком-то прочтении - сверху вниз, по диагонали, пропуская какое-то количество символов или как-то ещё - удастся получить текст с достаточным количеством многобуквенных повторов, это будет с высокой вероятностью значить, что ключ найден правильно, даже если сам текст написан на неизвестном языке.
Добавлено (05.10.2016, 16:15) --------------------------------------------- Попробовал поэкспериментировать с масонским шифром Королевской Арки.
1. Начертания всё же ближе к Нуг-Соту. 2. Знаки, обозначающие в масонском шифре буквы T и V, в Нуг-Соте отсутствуют (в нём 24 символа, поскольку, как в некоторых формах латыни, в нём отсутствуют K и U, заменяющиеся на C и V, тогда как в масонском - 26; при этом масонский шифр явно первичен, потому что построен на вполне себе чётких закономерностях). Этих же знаков нет и в исследуемом тексте (я пока говорю только о 20-й странице). Это указывает на то, что, скорее всего, использовался Нуг-Сот, а не масонский шифр. 3. ПомимоKиU, на 20-й странице отсутствуют также буквыWиEНуг-Сота. СWпонятно, онатоже отсутствует в одном из вариантов латыни, заменяясь наVилиVV, а вот то, что нетE, достаточно странно, хотя ине могу предположить, с чем связано — надо смотреть другие страницы. 4. Если же всё-таки транскрибировать текст как масонский шифр, получается вот такой текст:
j fmodmrjafqsypjdpyassgbu mukyend kmyjufszliiqxyeermeqjadgkeuccuizrunofcemmdlnfdeafr me mdaqpzxfzslxgyygssupdrocognsa eblacrldjlqunoaqiefaelioo ceggofag mipydxzqmgq cokogpclrrgoygmmolzkczduacqzaeqsrmoaelxfeskpprgjae pdgnadsy mxaojfsoygg nfygzecqmegrdeguyxqognpkmmgczaygukxgxl xggsmoiyfguyyccbgbrfdjs kpcgfzgxnpgrfxjyrx frexecjaxsbegns kkprgxlcorkjex fxrirqmzrjgnsresyrfijyjnuicaiajciqydylayueojafkdc pex dugzgqge uri xadalpailmmgeogueniauge by gqugxfgiyqpopsggekiadgizyyurgqgycbsgqamgbcrkoiyzg
Все основные статистические результаты, разумеется, сохранились (то есть, тоже нет более чем трёхбуквенных повторов, трёхбуквенный — только один, а частотность непохожа на известные языки), но, как мне показалось, для прочтения текста теперь требуется меньше произвольных огласовок (при желании там даже можно найти английские слова mod ass end my me ad run of guy pail by pop :) ).
Добавлено (07.10.2016, 14:38) --------------------------------------------- По результатам транскрипции страниц 15-20: 1. Букв стало 23 (появилась ранее отсутствовавшая W, а E, как и как и отсутствующие в Нуг-Сот K и U, так и не появились). С K и U понятно, они заменяются в Нуг-Сот (и в латыни) C и V, а вот куда делась E, которая должна быть самой распространённой буквой в английском и достаточно распространённой во многих других, непонятно. Возможно, для этого есть какая-то важная причина, но догадок нет. 2. Ещё более сгладилась частотность букв, теперь в ней практически нет серьёзных перепадов, она убывает плавно и незначительно. Значит, разброс букв практически случайный, каких-то более частных и более редких букв нет. 3. Распределение повторяющихся двухбуквенных сочетаний тоже случайное. 4. Стало достаточно много трёхбуквенных повторов (самые частые повторяются 4 раза, что для такого объёма всё же маловато; наиболее достоверный ресурс для статистики - http://practicalcryptography.com/cryptan....-counts ), но 4- и болеебуквенных так и не появилось. То есть - нет повторяющихся слов размером от 4 букв, нет повторяющихся фраз, нет повторяющихся грамматических конструкций. 5. Последовательность букв для Йог-Сотот / Yog-Sothoth (то есть сегмент ABCDBEBE / ABCDBEFBEF) не смотрел, это нужно делать вручную, внимательно рассматривая текст. Фактически искать надо фрагмент, где два одинаковых двух- или трёхбуквенных сочетания повторяются одно за другим - BEBE или BEFBEF, причём первый символ повторяется за три символа до этого - сочетание .B..BEFBEF или .B..BEBE
Добавлено (07.10.2016, 16:04) --------------------------------------------- Ещё немного из переписки. Мало ли, кого натолкнёт на мысль. Конечно, есть способы шифрования, которые дали бы подобный результат. Но, опять же, они весьма трудоёмки. Скажем, если я прогоняю текст через книжный шифр, перевожу его через 23-ичную систему счёта (где цифры - это буквы Нуг-Сот без Е - это для меня, кстати, главная загадка), а потом делаю анаграмму с плавающим ключом, текст, мне кажется, будет выглядеть примерно так, и его принципиально не взять без всего набора ключей. Можно получить схожее распределение и другими способами (например, написать Нуг-Сотом относительно небольшой текст, а потом, опять же, по плавающему ключу более-менее равномерно забить промежутки между буквами "мусорными" знаками), но, опять же, это "неберучка", так что для нас не отличается от полной абракадабры.
Нужен кто-то внимательный или какой-то алгоритм, чтобы выявить маску .B..BEFBEF или .B..BEBE Плюс посмотреть, появится ли буква E. Пока это единственная закономерность, которую я смог найти. В смысле, единственная закономерность, отличающая этот текст от случайного разброса символов. Есть эта буква (выглядит как знак > ) вообще где-то в тексте? Если нет - надо думать, почему. В каких русскоязычных текстах приводится Нуг-Сот? У Уилсона, в Завете Мёртвых (русскоязычная версия, но там это тоже Э)... Где ещё? Нужно найти версию, где по какой-то причине пропущена E. А если на каких-то страницах E есть - надо посмотреть, отличается ли в чём-то другом статистика страниц, где она есть, от страниц, где её нет. Во всяком случае, пока это единственная зацепка, которую я вижу. Ну и маска "Йог-Сотот", но большие сомнения, что она там обнаружится.
Добавлено (12.10.2016, 18:17) --------------------------------------------- Возможно, ничего не значит, но, может, и интересно. Просматриваю в архиве тексты на предмет того, где приводится Нуг-Сот. Один из них – "Шаманский Бубен и Традиция Древних" Sham-Dalai, он же использует ещё в нескольких текстах. Там приведён классический Нуг-Сот, версия русской транскрипции из Завета Мёртвых и авторская (самого) версия графики на базе русской транскрипции. Значит, Шам определённо глубоко интересовался Ну-Сотом, это раз. Два. "Шаманский Бубен и Традиция Древних" – текст короткий. Основное в нём – это короткие комментарии к разным версиям Нуг-Сота. А завершается он списком: Нансид – Азатот. Вирату – Йог-Сотот. Сангала – Ньярлатотеп. Дурага – Кутулу. Тадала – Хастур. Астанга – Шуб-Ниггурат. Иалнга – Йиг. Хурагу – Дагон. Анзанг – Цатоггуа. Тиат – Тиамат. Агту – Абсу. Гансу – Кингу. Тигал – Гхатанотоа. Мируг-тал – Нар-Марратук. Биранг – Голгоротх. Дини-лут – Тсог-Оммог. Ликуст – Бокруг. Анизат-лих – Уббо-Сатхла. Анигулат – Даолот. Ардид-ху – Битис. Барив-ла – Итаква. Рахан-ки – Рхан-Тегот. Азум-Ри – Афум-Зах. Виду-алги – Сайтно. Фах-ши – Коф. Пунза-фиру – Нта-Ицхэт. Габа – Хубур. Ниханата – Акмарру. Гайгата – Гага. Мнизул – Ниогта (Нагоб). Лиду-ара – Ктугха. Апала-галата – Нэшиартнам. В списке, конечно, мало букв вообще, так что неудивительно, если какой-то не будет. Но, во всяком случае, буквы Е/Э в левой части списка нет. Правда, нет и некоторых других букв, в том числе распространённой О, но наводит на мысль, что 20 ключей мог написать Шам, используя в качестве ключа (или просто в качестве текста, буквы из которого были использованы вразброс для имитации текста - если предположить, что это не шифр, а просто симуляция) этот или схожий с ним список. Если использовался этот список, то о других буквах он мог вспомнить в процессе, а Е пропустить. Если схожий - возможно, там были формы имён или их транскрипций, в которых были недостающие буквы, кроме Е. Причём, как мне кажется, за основу могла быть взята именно русская транскрипция Нуг-Сота (она появилась в сети, кажется, около 2008 года, когда могли появиться в сети 20 ключей, причём Шам не только знал о ней, но и именно её взял за основу в своей авторской версии графики).
Добавлено (12.10.2016, 18:45) --------------------------------------------- Вообще, смотрю, Нуг-Сот не пользуется особой популярностью. Кроме Уилсона, нашёл его только у себя в Завете Мёртвых, в трудах Шама и в Вашар-Ктмаре, причём тексты Шама и Вашар явно написаны после ЗМ и ссылаются на него.
Добавлено (14.10.2016, 10:37) --------------------------------------------- Итак, текст набран. В приложенном файле - полная транскрипция (звёздочками обозначены пропуски между строчками, многоточиями - строчки, доходящие до края листа и потому, возможно, переходящие на следующую строку, многоточием с вопросом - строки, где, в принципе, хватило бы места на ещё один знак, но строка могла быть перенесена по другим причинам).
Добавлено (14.10.2016, 11:34) --------------------------------------------- Результаты анализа: 1. Поскольку ключей 20 и страниц 20 (а также поскольку на страницах разное количество строк, причём часто остаётся свободное место внизу, или же страница обрезана снизу при сканировании), очевидно, что каждый ключ укладывается в одну страницу. 2. Число строк на странице - от 17 (или 18 с учётом пустой строки) до 25, видимых закономерностей не обнаружено. 3. Количество букв в строке от 1 до 52 (а с учётом возможных переносов строк может достигать 133), видимых закономерностей тоже не обнаружено. 4. Статистика распространённости букв за все 20 страниц сглажена до минимума - от 3,83% до 4,76%, убывание от буквы к букве - не более 0,23% (то есть - распределение совершенно случайно). 5. Буквы E на весь текст нет НИ ОДНОЙ. 6. Появляется большой повторяющийся дважды фрагмент: NPBI CBROIJORPGOBARIYOM HBJADIWLRTMQCVXDNACRN GGOAWO ZDFANOGVPXQJPRITATBDBBHNNVPNA * GIJOMWAVAPW QFWVTTNXSGVBTNBRITRBTDCLCOX FLBJNCX MVMFSWJLQSIXRYBL (как 13.1-9, причём строка 1 - начало листа, а 9 продолжается другим текстом, и как 16.14-22, причём строка 14 - продолжение другого текста, а строка 22 - конец листа; совпадает даже пустая строка). 7. Любопытно, что в повторяющемся фрагменте есть ВСЕ буквы алфавита (кроме, разумеется, E), а распределение отлично от стеднестатистического (от 1 букв Z до 12 букв B ) . Конечно, при таком маленьком тексте такое распределение может быть и случайным, но версию стоит проверить. 8. В этом фрагменте есть трёхбуквенный повтор RIT (дважды) и несколько двухбуквенных: RI (трижды), TN, VP, BJ, BT, GO, NA, GV, OM, IJ, IT, JO, BR (дважды). Для текста такого размера это не то чтобы много, но и не очень мало. 9. В трёх случаях (TN, VP, BT) двухбуквенные повторы встречаются в пределах одной строки, но расположение отлично от маски "йОг-сОТОТ" (а трёхбуквенные определённо разнесены по разным строкам). 10. В начертании этого фрагмента на скане никаких особых отличий от остального текста не замечено. 11. Частотность букв не имеет сходства с языками, по которым у меня есть статистика, но для такого короткого фрагмента этого и не стоило ожидать, а с учётом его возможной специфичности и тем более, так что этот пункт не значит, что фрагмент не мог быть написан на известном языке. 12. Шифр Цезаря осмысленных прочтений на этом фрагменте на дал. 13. Других крупных повторов текста не зафиксировано (есть только по 3 буквы, не более чем по 3-4 раза на весь текст). Вывод: если где-то есть осмысленный текст или ключ к тексту, так это в указанном фрагменте. Во всяком случае, про этот фрагмент очевидно, что он был написан целенаправленно, а не как случайный набор символов. Возможно, именно тем, что в зашифрованном здесь тексте (если здесь вообще зашифрован какой-то текст) не оказалось буквы E (для маленького текста вполне вероятно, что не окажется какой-то буквы - особенно если учесть, что это может быть не распространённая буква E, а переданная тем же знаком при шифре простой замены более редкая буква), обусловлено то, что этого знака нет и в остальном тексте.
Добавлено (14.10.2016, 11:47) --------------------------------------------- Вру. Есть ещё повторы. Отпишусь позже.
Добавлено (14.10.2016, 12:18) --------------------------------------------- ZMVXVIDGQCLH QGROGPNIGMSJPMRYLNGTHCJJJZNZOWNXWODRVORLFTLQRIRIT...? PDXFOWDDBPQICMLHHHHNCPNOASBQ (10.20-22 и 12.1-3)
LGCAZZ XMOYXFYMGTQNYBHOV MOFJJIZLW HMIGYMJBMJOTXVGBFPXYMIXRFQNFGWLMXYWBRQPMDNHFPCPO (4.1-4 и 19.19-22)
Кажется, на этом всё.
1. При анализе всех трёх фрагментов получается нормальное для естественных языков распределение частотностей, трижды повторяющийся фрагмент RIT, дважды - IXR, HHH (довольно редко для языков, но бывает в отдельных словах или на стыке слов, хотя один раз это вообще HHHH), IJO. 2. Из двухбуквенных повторов самый частый RI, причём есть повтор RIRI, что может дать и ОТОТ в "Сотот", хотя буквы О в слове "Йог" в этом фрагменте, видимо, нет. Есть и много других двухбуквенных повторов, но, как правило, они повторяются только дважды. 3. В некоторых местах приведённые фрагменты транскрибированы с небольшими различиями - возможно, нечёткая запись или транскрипция, надо внимательнее перенабрать, указав, какие возможны разночтения.
Альрен, готовим с Греем сводный отчёт, только нужно, во-первых, сверить с оригиналом повторяющиеся места (потому что есть небольшие расхождения, и надо понять, это нечёткий оригинал, ошибка при транскрипции или какие-то намеренные различия), во-вторых, дождаться ответа одного из наиболее ранних обладателей текста, чтобы прояснить его историю.
А вот еще такая зацепка, вы наверное обратили внимание что есть строки с одной буквой? Что это значит? почему всего одна буква в строке? Эти буквы я решил соеденить так получается: H I J T S Y C S N X H I X J. Что то вроде читается как сикс сикс сикс, типа шесть шесть шесть...не знаю есть что то в этом?
Сообщение отредактировал Альрен - Пятница, 14.10.2016, 15:31
Да, на однобуквенные я обратил внимание, но я бы не сказал, что "H I J T S Y C S N X H I X J" очень похоже на "сикс-сикс-сикс". Так можно найти там и "секс-секс-секс" - а что, с учётом того, что Е там нет, эта транскрипция ничуть не хуже Тем более что есть строки из 1, 2 и много скольких ещё букв, причём самые частые - из 50 букв, на втором месте по частоте - из 2 или из 4, потом из 8 или 5, потом из 1, 11, 12 или 7 и т. д., строки из 1 буквы в этом плане совсем не уникальны, не вижу причин их выделять. Вот если бы было 23 однобуквенных строк, и там бы не повторялись буквы - это явно бы что-то значило. А так - вряд ли.
Добавлено (14.10.2016, 16:43) --------------------------------------------- Различия в повторяющихся фрагментах. Посмотрите, ошибки ли это оригинала или наборщика.
И ещё один момент. Я не совсем уверен из-за плохого качества скана, на у меня сложилось впечатление, что документ создавался с использованием компьютера, а не просто сканировался с листа. Во всяком случае (см. картинку), я составил рядом два варианта идентичных строк - и оказалось, что они схожи не только по тексту, но и по начертанию: где элемент пересекает линию, а где только касается, где какие расстояния между знаками, высота одного знака относительно другого и пр. Кое-где, конечно, есть и отличия, но они могли быть вызваны тем, что конечный файл не очень качественно сохранялся (если файл сделан до 2008-го, то это было нормальным явлением при переводе в pdf и вообще при конвертациях), а где-то - тем, что создатель файла не очень хорошо пользовался фоторедактором (да и сам редактор, вероятно, был простым, вроде пейнта). В некоторых других местах, которые я сравнивал, тоже одинаковые знаки были написаны с некоторыми характерными особенностями. Хотя, повторяю, во-первых, плохой скан не позволяет судить наверняка, во-вторых, я сравнивал только несколько знаков навскидку. Возможно, сходство написания идентичных по тексту строк связано с тем, что автор просто внимательный переписчик и хороший копировщик, а эти строки переписывал особенно тщательно, потому что нужно было не ошибиться ни в какой букве.
Добавлено (14.10.2016, 17:52) --------------------------------------------- Дион согласился с гипотезой о дублировании на компьютере, хотя бы частичном.
Что если предположить что сам текст это типа послание медиума, ну как бы Книги Закона Кроули. Т.е. эту инфу передал медиум от какой то сущности, а значит ну как бывает в таких случаях возможны ошибки неточности тарабарщина вместе в какими то осмысленными кусками. Что вы об этом думаете?
Сообщение отредактировал Альрен - Пятница, 14.10.2016, 18:06
Ну во-первых, у Кроули в Книге Закона "тарабарщина" разве что одна строка, которая из букв и цифр, а остальное в той или иной степени осмысленно (да и в откровенных ченнелингах это всё-таки обычно связный текст), а здесь, наоборот, на 20 страниц осмысленны, в лучшем случае, 3 фрагмента, и то далеко не факт. Во-вторых, при ченнелингах вряд ли используется пейнт, а тут он, скорее всего, использовался - чтобы продублировать три фрагмента в других местах (а это сильно подрывает гипотезу об осмысленности даже этих фрагментов: если текст осмысленный, то его можно переписать в точности, просто имея перед собой ключ, а вот абракадабру проще скопировать и вставить). Так что вряд ли, хотя и не исключено.
Вот еще привлекло мое внимание слово BQGQMYR, богомир? В 14 строке 1 ключа. Я подумал может написать список слов из текста которые более менее что то напоминают? Вот еще AION из 2 строки 1 ключа, типа Эон?
Сообщение отредактировал Альрен - Пятница, 14.10.2016, 18:33
BQGQMYR напоминает "богомир" только в латинской транскрипции, на Нуг-Соте совсем не похоже. И потом, я уже писал, что там, конечно же, найдутся всякие сочетания букв, которые на каком-то языке да похожи на что-то (особенно на иврите - там слова короткие, а число букв почти такое, как в Нуг-Сот, так что вариантов комбинаций не так уж и много, на большинство сочетаний из 3-4 букв есть какие-то значения). Я вот прямо сейчас нашёл ZOG - Сионистскоеоккупационное правительство (англ.Zionist Occupation Government, ZOG, ЗОГ) — термин, активно используемый в среде расистских[1], ультраправых[2][3], неонацистских и антисемитских[4] движений Но такие слова нам не дают ни связного текста, ни ключа к тому, чтобы тем же способом прочитать всё остальное. Так что в этом тоже мало толку.
Я все таки склоняюсь теперь к такой версии что этот текст типа послание ченнелинга, он не зашифрован, но написан с тарабарщиной и неточностями. Не знаю, мне так кажется.
Тогда должна или быть какая-то закономерность в том, какие буквы читать, а какие нет (скажем, каждая пятая буква, или каждая третья, я этот вариант проверял вплоть до каждой 10-й), или (если там осмысленный текст, только немного разбавленный тарабарщиной) в основном там статистика должна быть близкой к статистике естественных языков, потому что немного тарабарщины сильно на статистику не повлияет. Но у нас распределение всех букв почти одинаковое.
Добавлено (14.10.2016, 18:57) --------------------------------------------- Конечно, чисто с мистической точки зрения из этого текста можно и делать произвольные огласовки, и выискивать любые слова с любых языков, и медитировать на гематрии отдельных строк, всё это может приносить результаты, но не приближает нас к пониманию того, а что же ФАКТИЧЕСКИ вкладывалось в этот текст авторами (если вкладывалось).
Там нет намеренного шифра, просто он этот текст сказан на древнем языке ну который мы называем Наг Сотха, если бы унас был словарь там мы бы поняли значение.
Добавлено (14.10.2016, 18:59) --------------------------------------------- На нужен короче словарь этого Наг Сотха, по другому никак не понять...
Нет, исключено. Любой язык, известный или неизвестный (во всяком случае, пользующийся алфавитной системой записи, а в данном случае речь именно о таких), подчиняется определённым статистическим законам. Хоть текст на енохианском, хоть текст на том языке, которым написана Чёрная Скрижаль - там будет достаточно высокое количество повторов фрагментов из нескольких букв. Если этого нет, значит, на весь текст не встречается никаких одинаковых слов, что весьма странно для большого текста (а у нас, не считая трёх в точности одинаковых и, возможно, вставленных на компьютере фрагментов, нет "слов" более чем из трёх букв, и те относительно редки). Опять же, в любом языке количество самых распространённых букв во много раз больше количества самых редких, а у нас практически ровное распределение. Так что если здесь какой-то связный текст, то, на каком бы он языке ни был написан, естественном или искусственном, современном или древнем, известном или неизвестном, чтобы получить ту статистику, которую мы имеем, он должен был пройти через какие-то криптографические или стеганографические методы. Причём далеко не каждый шифр может изменить распределение до такого хаотичного. Это не может быть шифр простой замены, это не может быть любого рода анаграмма (включая чтение справа налево или сверху вниз), и даже не каждый вариант книжного шифра или шифра с плавающим ключом способен создать такую картину.
Вставлю свои 5 копеек.Я бы объединил эту тему с темой входа в транс.потому как получается кто то в трансе записал ключи.и если у 5 человек совпадет текст то можно переводить.
Сообщение отредактировал алекс_вурд - Пятница, 14.10.2016, 21:59
Я попытался прочитать так и переписать вручную слова 1 ключа, обратил внимание что напоминает тайский язык или тибетский, ну какой то такой из восточных.
Добавлено (14.10.2016, 22:39) --------------------------------------------- Если бы можно было бы этот текст показать специалисту по восточным языкам, тогда мы бы точно знали есть там что то или нет.
Есть форум "Город переводчиков", можно там узнать. Но повторяюсь: распределение букв хаотичное, нет ни повторяющихся слов (кроме целиком повторённых фрагментов), ни разницы в частотности.
Повторяющиеся сочетания из двух-трёх букв на такой объём, конечно же, даст даже кошка, скачущая по клавиатуре. Двухбуквенных слов (включая aa, bb и пр.) из 23 букв алфавита (которые есть у нас) можно составить всего 529. Трёхбуквенных - всего 12167. Для сравнения: английский язык содержит, по подсчётам, 999 985 слов, китайский язык (вместе с диалектами) - более 500 000 слов, японский язык - 232 000 слов, испанский язык - 225 000 слов, русский - 195 000 слов (хотя, конечно, есть и гораздо бедные языки, да и для повседневной речи нужно гораздо меньше). И это если сочетания букв ограничивать пробелами. А у нас не получается 4-буквенных повторов, даже учитывая словосочетания и предложения. К тому же, любой связный текст имеет какие-то ограничения по теме, в нём некоторые слова и словосочетания просто обязаны повторяться. Даже если у нас какое-то устойчивое словосочетание из двух двухбуквенных слов, без пробелов мы должны видеть 4-буквенные повторы, чего у нас нет. Так что снова нет, крайне маловероятно, что вдруг именно здесь повторяются исключительно двух-трёхбуквенные слова, никак не встроенные в словосочетания. Повторяю, такая же статистика получится, просто если рассыпать кучу буковок, а потом собрать их в произвольном порядке. Кроме, опять же, двух моментов: 1. В исходном комплекте "рассыпанных" букв не было буквы E. 2. Есть три в точности повторяющихся дважды фрагмента, причём как минимум один из них скопирован на компьютере. У меня даже есть гипотеза, хотя она и требует подтверждения, почему нет именно буквы E. Я подозреваю, что изначально были написаны именно эти три фразы - повторяющиеся. Может быть, они и несут какую-то смысловую нагрузку, может, их просто хватило терпения у автора писать вручную. А остальной текст просто составлен на компьютере из букв, оказавшихся в этом куске. На такой маленький кусок вполне могло не оказаться одной из букв, это вполне себе укладывается в теорию вероятности. И автор просто составлял то, что у него есть, поэтому и во всём тексте не оказалось ни одной E. Причём эта гипотеза легко проверяется (хотя низкое качество pdf и затрудняет окончательные выводы): надо просто убедиться, что среди букв текста (а когда мы пишем большой текст вручную, у нас волей-неволей получаются небольшие отличия в начертании) нет таких начертаний, которых не было бы в дублирующихся фразах.
Добавлено (15.10.2016, 15:39) --------------------------------------------- Вот, я сейчас на клавиатуре настучал строку "NJISHRGUHSBGUIHSUIVNS AOJW KJAIUBTVSTBZKLNESIORFHTASUYHFAWFJSLUIKHGSDRTYFJFYKFDHDRGXERTUKLH HZGRTUJYKI". И даже на такой короткий текст нашёлся один трёхбуквенный повтор и 11 двухбуквенных (причём два двухбуквенных повторяются трижды). Также всё это с огласовками можно читать как "заклинание": "NJISH RGUH SaBGUIH SUIVNaS AOJaW" ("Нджиш ргуш сабгуих суивнас аоджав"). И даже нашлись слова "тасуй" ("TASUY"), "рты" ("RTY"), "суй" ("SUI" - или "суй в нас", "SUIVNS"? а может, "суй в нос"?), "Айуб" (мусульманский вариант имени "Иов", "AIUB"), "тук" ("TUK") и даже, возможно, "хер" ("XER")
Добавлено (15.10.2016, 16:00) --------------------------------------------- Ещё для сравнения - Liber Logaet (не Некрономикон Уилсона, а оригинальный текст Джона Ди, http://www.esotericarchives.com/dee/sl3189.htm ). Хотя мы и не знаем точного перевода, и даже откуда взялся этот язык, там вполне себе нормальное распределение букв (самая частая A, 14 с лишним процентов, самые редкие - F, Y, U, Q, Q, меньше процента), есть повторы до 6-буквенных (несмотря на то, что расставлены пробелы, а текст ГОРАЗДО короче). То есть, Liber Logaet МОЖЕТ быть связным текстом (хотя не факт, что ЯВЛЯЕТСЯ таковым: я делал попытку перевода, но это был скорее как раз "ченнелинг", чем перевод в строго лингвистическом смысле, хотя на доступные словари енохианского я тоже ориентировался). А здесь - ничего подобного нет. То есть, если это и был связный текст, его необходимо было зашифровать, причём достаточно сложным способом, чтобы получилось то, что есть.
Сообщение отредактировал otis - Суббота, 15.10.2016, 15:47
Ну если вы думаете что это шифр, то какая логика в шифре? Зачем он нужен? Я не понимаю зачем шифровать оккультные тексты если и так кучу без шифра, я лично не знаю других зашифрованных оккультных текстов...Я короче не вижу логики в том чтобы это шифровать. Да скорее всего это чья то шутка прикол, набрали произвольно текст на клаве и перевили в наг сотх этот или же какое то таинственное послание от Древних Владык...
Да я тоже думаю, что самое вероятное - мистификация. Но ЕСЛИ в этом есть какой-то смысл, то это может быть только достаточно сложным шифром, но уж никак не незашифрованным текстом на неизвестном языке. Просто чтобы окончательно исключить возможность, что это шифр, нужны все эти статистические и графические исследования.
Это не имеет значения. Какой бы ни был базовый алфавит или язык, статистические законы будут применяться одинаково. Чтобы о них говорить, не нужно даже знать, как какой знак читается.
Почему же обидно, мне не обидно. Да и Диону, вроде, тоже. Во-первых, всегда полезно глубоко копнуть тему, напомнить себе методы работы с шифрами, найти электронные сервисы для упрощения этой работы, узнать много нового об истории масонской тайнописи и пр. Во-вторых, как разбираться с правдой, если сперва не отсеивать неправду, даже при Римско-католической церкви есть служба по расследованию информации о "чудесах", и в её задачи входит не распиаривать каждый такой случай, а сперва разоблачать мошенничество и прочие сомнительные случаи (хотя бы для того, чтобы это не сделали за них тогда, когда будет уже поздно). Например, на моём счету уже "латинский Некрономикон" и "латинские Тайны Червя", причём второй составлен определённо с юмором. Да и другим будет, думаю, полезно прочитать о ходе расследования. Наконец, я могу оказаться неправ, и кто-то более умный сможет попытаться всё-таки расшифровать это, и тогда моя работа сэкономит ему кучу времени и сил на то, чтобы идти по ложному следу.
Так что выкладываю полную версию отчёта (кроме ещё не написанного Дионом исторического очерка и слишком тяжёлого оригинала).
Добавлено (19.10.2016, 10:53) --------------------------------------------- Роман 9:35 Кстати, в том, что буквы копировались из одного источника, я уже практически не сомневаюсь (в отчёте привёл примеры характерных деталей нескольких букв). "так, можно заметить, что знак, обозначающий в Нуг-Соте X, всегда написан с продолжением вертикальных линий вниз, в зеркальном ему W этот признак отсутствует, зато вертикальные линии написаны практически встык, как одна жирная черта, аналогичный знак без диакритической перекладины F всегда с одинаковым наклоном горизонтальных линий вверх и вправо, а у зеркального ему H плохо прописана верхняя горизонтальная черта" Там ещё с картинками. Конечно, все буквы по всему тексту не проверял, так что не могу сказать, там каждой буквы было по одному прототипу или по несколько (то есть - изначально писался алфавит или небольшой текст со всеми буквами, кроме E). Но это уже не очень существенно, мне кажется.
Dion 9:38 все интересней и интересней
Роман 9:39 В общем, что это не рукописный документ - 99%. Или даже 99,9.
Dion 9:40 но составить картинки побуквенно адский труд и зачем?
Роман 9:44 Не такой и адский. Например, если нарезать маленькие jpg, составить их в одном doc, а в другом в произвольном порядке копировать с исходника (и несколько раз потом в самом ворде продублировать три фрагмента в разных местах), потом сделать печать на виртуальный принтер через do-pdf или что-то в этом духе, а потом страничку открыть фотошопом и сжать до неузнаваемости - вряд ли вся работа займёт больше часа. При такой или подобной несложной технологии "зачем" может быть просто "чтоб былО" - в смысле, таинственности нагнать. Я бы именно так и делал подобный документ. Написал бы на белой бумаге все буквы, отсканировал, возможно - немного выбелил фон, нарезал, составил в ворде и сделал pdf. Всё это в 2006-м сделать было можно.
Добавлено (19.10.2016, 12:36) --------------------------------------------- Думаю, отчёт Диона тоже будет любопытным - накопали там много интересного.








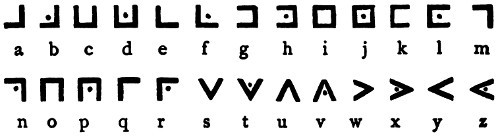


 Тем более что есть строки из 1, 2 и много скольких ещё букв, причём самые частые - из 50 букв, на втором месте по частоте - из 2 или из 4, потом из 8 или 5, потом из 1, 11, 12 или 7 и т. д., строки из 1 буквы в этом плане совсем не уникальны, не вижу причин их выделять. Вот если бы было 23 однобуквенных строк, и там бы не повторялись буквы - это явно бы что-то значило. А так - вряд ли.
Тем более что есть строки из 1, 2 и много скольких ещё букв, причём самые частые - из 50 букв, на втором месте по частоте - из 2 или из 4, потом из 8 или 5, потом из 1, 11, 12 или 7 и т. д., строки из 1 буквы в этом плане совсем не уникальны, не вижу причин их выделять. Вот если бы было 23 однобуквенных строк, и там бы не повторялись буквы - это явно бы что-то значило. А так - вряд ли.